



Bandwidth yang digunakan dalam UMA ke memori dibatasi karena menggunakan pengontrol memori tunggal. Motif utama munculnya mesin NUMA adalah untuk meningkatkan bandwidth yang tersedia ke memori dengan menggunakan beberapa pengontrol memori.
Grafik perbandingan
| Dasar untuk perbandingan | UMA | NUMA |
|---|---|---|
| Dasar | Menggunakan pengontrol memori tunggal | Pengontrol memori berganda |
| Jenis bus yang digunakan | Tunggal, banyak, dan palang | Pohon dan hierarkis |
| Memori mengakses waktu | Sama | Perubahan sesuai dengan jarak mikroprosesor. |
| Cocok untuk | Aplikasi tujuan umum dan pembagian waktu | Aplikasi waktu nyata dan waktu kritis |
| Kecepatan | Lebih lambat | Lebih cepat |
| Bandwidth | Terbatas | Lebih dari UMA. |
Definisi UMA
Sistem UMA (Uniform Memory Access) adalah arsitektur memori bersama untuk multiprosesor. Dalam model ini, satu memori digunakan dan diakses oleh semua prosesor yang menyajikan sistem multiprosesor dengan bantuan jaringan interkoneksi. Setiap prosesor memiliki waktu akses memori (latensi) dan kecepatan akses yang sama. Itu dapat menggunakan salah satu dari bus tunggal, beberapa bus atau switch palang. Karena menyediakan akses memori bersama yang seimbang, ia juga dikenal sebagai sistem SMP (Symmetric multiprocessor) .
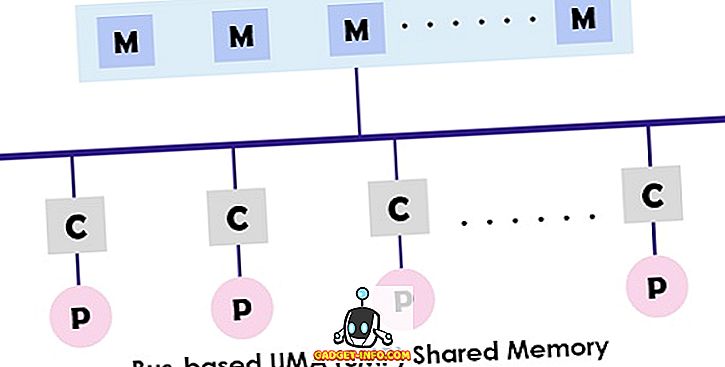
Desain khas SMP ditunjukkan di atas di mana setiap prosesor pertama kali terhubung ke cache kemudian cache dihubungkan ke bus. Akhirnya bus terhubung ke memori. Arsitektur UMA ini mengurangi pertentangan untuk bus dengan mengambil instruksi langsung dari cache yang diisolasi secara individu. Ini juga memberikan probabilitas yang sama untuk membaca dan menulis untuk setiap prosesor. Contoh khas dari model UMA adalah server Sun Starfire, server Compaq alpha dan HP v series.
Definisi NUMA
NUMA (Non-uniform Memory Access) juga merupakan model multiprosesor di mana setiap prosesor terhubung dengan memori khusus. Namun, bagian-bagian kecil dari memori ini bergabung untuk membuat ruang alamat tunggal. Poin utama untuk direnungkan di sini adalah bahwa tidak seperti UMA, waktu akses memori bergantung pada jarak di mana prosesor ditempatkan yang berarti waktu akses memori yang berbeda-beda. Ini memungkinkan akses ke salah satu lokasi memori dengan menggunakan alamat fisik.
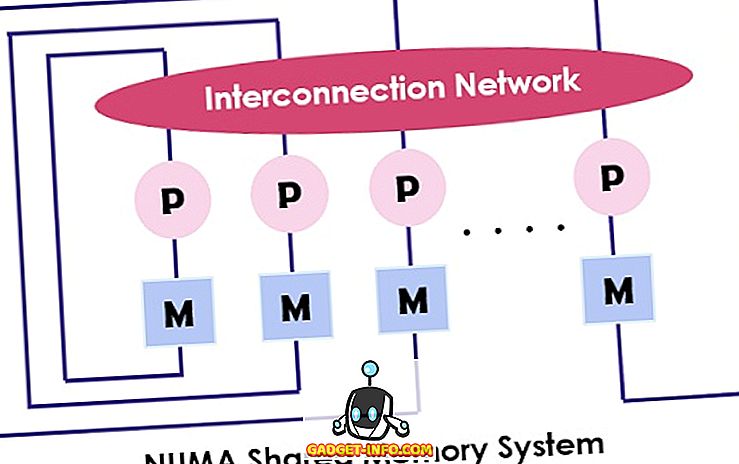
Seperti yang disebutkan di atas arsitektur NUMA dimaksudkan untuk meningkatkan bandwidth yang tersedia ke memori dan yang menggunakan beberapa pengontrol memori. Ini menggabungkan banyak inti mesin menjadi " node " di mana setiap inti memiliki pengontrol memori. Untuk mengakses memori lokal di mesin NUMA, inti mengambil memori yang dikelola oleh pengontrol memori dengan simpulnya. Sementara untuk mengakses memori jarak jauh yang ditangani oleh pengontrol memori lainnya, inti mengirimkan permintaan memori melalui tautan interkoneksi.
Arsitektur NUMA menggunakan pohon dan jaringan bus hirarkis untuk menghubungkan blok memori dan prosesor. BBN, TC-2000, SGI Origin 3000, Cray adalah beberapa contoh arsitektur NUMA.
Perbedaan Utama Antara UMA dan NUMA
- Model UMA (memori bersama) menggunakan satu atau dua pengontrol memori. Sebaliknya, NUMA dapat memiliki beberapa pengontrol memori untuk mengakses memori.
- Bus tunggal, banyak dan palang digunakan dalam arsitektur UMA. Sebaliknya, NUMA menggunakan hierarki, dan jenis pohon bus dan koneksi jaringan.
- Dalam UMA, waktu mengakses memori untuk setiap prosesor adalah sama, sementara di NUMA waktu mengakses memori berubah ketika jarak memori dari prosesor berubah.
- Aplikasi tujuan umum dan pembagian waktu cocok untuk mesin UMA. Sebaliknya, aplikasi yang tepat untuk NUMA adalah sentris waktu-nyata dan kritis-waktu.
- Sistem paralel berbasis UMA bekerja lebih lambat daripada sistem NUMA.
- Ketika datang ke bandwidth UMA, memiliki bandwidth terbatas. Sebaliknya, NUMA memiliki bandwidth lebih dari UMA.
Kesimpulan
Arsitektur UMA menyediakan latensi keseluruhan yang sama untuk prosesor yang mengakses memori. Ini tidak terlalu berguna ketika memori lokal diakses karena latensi akan seragam. Di sisi lain, di NUMA setiap prosesor memiliki memori khusus yang menghilangkan latensi ketika memori lokal diakses. Latensi berubah karena jarak antara prosesor dan memori berubah (yaitu, Tidak seragam). Namun, NUMA telah meningkatkan kinerja dibandingkan dengan arsitektur UMA.





